

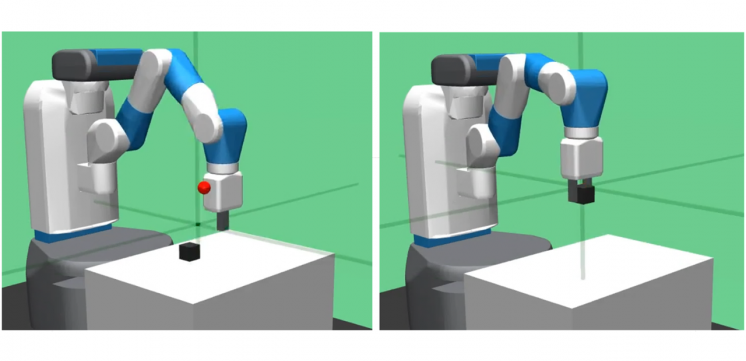
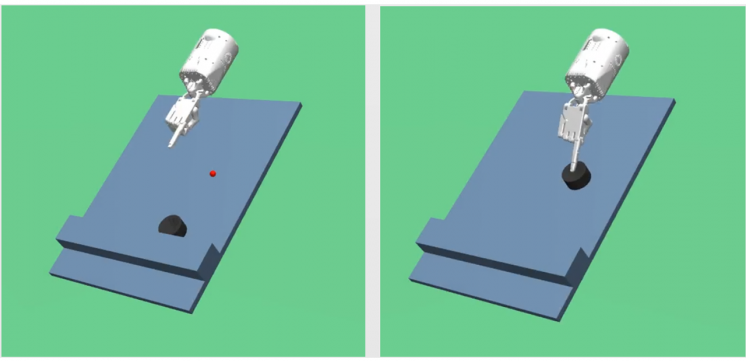
Compliance of the human finger plays a crucial role during interaction with unstructured environments. Human fingers freely adjust their stiffness depending on the situation or application. While stiffness control has been previously implemented in robotic hands, exactly how to choose a robot’s inherent or passive stiffness is an open question. High stiffness (i.e., industrial manipulators) improves precision but lacks flexibility and may damage the environment, whereas low stiffness (i.e., soft robotic fingers) improves robustness but suffers from inaccuracy. On the other hand, reinforcement learning has been widely studied to acquire appropriate controllers for certain situations using model-free approaches based on neural networks. However, learning with a physical robot is often expensive in terms of time and effort due to its sampling nature and therefore often infeasible. Thus, the goal of this project is to learn a robust, dexterous controller through safe reinforcement learning that not only outperforms conventional approaches but is also deployable and realizable with physical robots.
In this process, we plan to utilize the learned controller to make informed hardware design choices such that the performance is guaranteed, but at the same time stability and efficiency are optimized. From our research, the actuator passivity is determined by the design choices in both hardware and software and can be used to derive conservative stability criteria. Such criteria provide the user with a useful insight on how the hardware and controller complement each other in pursuit of the desired performance.
We have shown that parallel compliance can be a viable option to optimize and help reach passivity-based stability. We have also proposed a new learning scheme that exerts far less force during and after the learning phase compared to any existing approaches which indicates improved safety. The sampling complexity is alleviated by utilizing expert demonstration data, and the learned policy outperforms the demonstration gradually within training. The expanded action space of the proposed policy is compensated by the augmentation process of the demonstration data. Overall performance will be evaluated through comparison between the existing approaches and the proposed approach using a physical robot.

Collaborators:
Scott Niekum, Personal Autonomous Robotics Lab (PeARL), UT Austin (https://www.cs.utexas.edu/users/ai-lab/lab-view.php?LabID=20)
